- Полное руководство по сравнению методов импутации данных: какой выбрать?
- Что такое импутация данных?
- Классификация методов импутации
- Дескриптивные методы
- Среднее значение
- Медиана
- Мода
- Модельные методы
- Регрессия
- Модель классификации
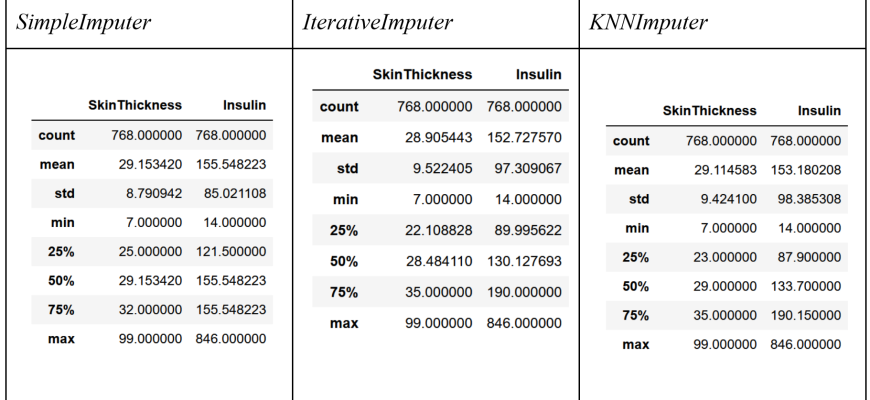
- k ближайших соседей (kNN)
- Гибридные и современные методы
- Автоэнкодеры
- Бустинг и буферизация
- Выбор метода: что учитывать?
- Практические советы по выбору метода
Полное руководство по сравнению методов импутации данных: какой выбрать?
В современном мире обработки данных проблема отсутствующих значений остается одной из самых острых. Неважно, идем ли мы в глубины аналитики или объединяем разрозненные источники информации, рано или поздно сталкиваемся с ситуацией, когда часть данных просто отсутствует или повреждена. Именно тогда на сцену выходит импутация — процесс замены пропущенных значений на разумные альтернативы, чтобы сохранить целостность и качество анализа. Но как выбрать правильный метод импутации? Какие есть подходы и чем они отличаются друг от друга? В этой статье мы подробно разберем все популярные методы, сравним их преимущества и недостатки, а также дадим рекомендации по выбору наиболее подходящего варианта в различных ситуациях.
Что такое импутация данных?
Импутация — это процедура заполнения пропущенных или недостающих значений в наборе данных путём вставки оценочных или предположенных значений. Целью этого процесса является устранение пропусков, минимизация потерь информации и повышение точности статистического анализа или машинного обучения. Важно понимать, что неправильный выбор метода импутации может привести к смещению результатов, искажениям в данных и снижению достоверности аналитики.
Для лучшего понимания стоит рассмотреть пример. Представьте, что у вас есть таблица с информацией о пациентах: возраст, пол, уровень холестерина. В некоторых записях отсутствует показатель холестерина. Варианты заполнения этой пропущенной информации, использовать среднее значение, медиану, значения из других строк и т.д..
Классификация методов импутации
Все существующие методы можно условно разделить на несколько групп по принципу простоты, точности и сложности реализации:
- Дескриптивные методы, простые и быстрые, основаны на статистических характеристиках данных
- Модельные методы — используют сложные модели для предсказания пропущенных значений
- Гибридные методы — комбинируют преимущества первых двух подходов
Рассмотрим каждую из групп подробнее.
Дескриптивные методы
Это самые простые и широко используемые методы, которые применяются, когда объем данных небольшой, а требования к точности не являются критическими.
Среднее значение
Наиболее популярное решение — заполнение пропусков средним арифметическим по столбцу. Этот метод быстро реализуем и подходит для нормальных распределений данных, где среднее значение репрезентативно.
Медиана
Используется для данных с асимметричным распределением или с наличием выбросов. Медиана менее подвержена влиянию экстремальных значений.
Мода
Подходит для категориальных признаков, когда заполняется наиболее часто встречающееся значение.
| Метод | Тип данных | Преимущества | Недостатки |
|---|---|---|---|
| Среднее | Непрерывные | Простое и быстрое | Может искажать распределение при выбросах |
| Медиана | Непрерывные | Менее чувствительна к выбросам | Может уменьшить вариативность |
| Мода | Категориальные | Соответствует наиболее частому значению | Не подходит для числовых данных |
Модельные методы
Эти методы предполагают создание специальных моделей, которые на основе известных данных предсказывают пропущенные значения. Они более сложные, зато позволяют сохранить взаимосвязи между признаками и обеспечивают более точную импутацию.
Регрессия
Используется для непрерывных данных. Например, модель линейной регрессии предсказывает уровень холестерина на основе возраста, пола и других признаков.
Модель классификации
Подходит для категориальных и бинарных признаков. Используют, например, деревья решений или логистическую регрессию для определения типа категории.
k ближайших соседей (kNN)
Этот метод ищет схожие записи без пропусков и использует их значения для заполнения пропусков. Очень эффективен, когда есть хорошие похожие образцы в данных.
| Метод | Тип данных | Преимущества | Недостатки |
|---|---|---|---|
| Регрессия | Непрерывные | Учитывает взаимосвязи между признаками | Требует обучения модели и наличия данных для этого |
| Классификация | Категориальные | Обеспечивает логическую связность | Может переобучаться при маленьких выборках |
| kNN | Любые | Легко реализуем и понятен | Медленный при больших данных, чувствителен к выбросам |
Гибридные и современные методы
На грани между простотой и сложностью находятся методы, которые используют ансамбли моделей, машинное обучение или даже нейронные сети для импутации данных. Эти подходы обеспечивают максимально точное восстановление пропусков, особенно в больших и сложных наборах данных.
Автоэнкодеры
Используются для восстановления данных путём обучения нейронной сети, которая «запоминает» исходные признаки и восстанавливает пропущенные значения.
Бустинг и буферизация
Комбинируют несколько слабых моделей для повышения точности при импутации.
| Метод | Тип данных | Преимущества | Недостатки |
|---|---|---|---|
| Автоэнкодеры | Разные | Высокая точность, сохраняет сложные зависимости | Требует больших вычислительных ресурсов |
| Бустинг/баггинг | Разные | Улучшенная стабильность и точность | Сложность настройки |
Выбор метода: что учитывать?
При выборе метода импутации важно учитывать несколько факторов:
- Тип данных — числовые, категориальные, временные ряды
- Размер набора данных — малый, средний или большой
- Природа пропущенных значений — случайные или систематические
- Требуемая точность — важный критерий, если в аналитике критичны малейшие погрешности
- Время и ресурсы, сложные модели требуют больше вычислительных мощностей
Практические советы по выбору метода
Чтобы выбрать правильный метод, рекомендуется провести сравнение на тестовых данных или использовать кросс-валидацию. В большинстве случаев началом будет простая импутация средним или медианой, а при необходимости, переходить к более сложным моделям.
Выбор метода импутации зависит от целей анализа, характеристик данных и доступных ресурсов. Важно помнить, что любая имтутация — это предположение, и правильная оценка её эффективности поможет избежать ошибок в дальнейшей аналитике. В сложных случаях рекомендуется использовать модельные или гибридные подходы, а для быстрого и простого заполнения — дескриптивные методы.
Вопрос: Почему важно правильно выбрать метод импутации данных, и какие последствия могут быть при неправильном выборе?
Правильный выбор метода импутации обеспечивает сохранение взаимосвязей между признаками, предотвращает искажения результатов анализа и повышает точность моделей. Неправильный выбор, например, применение среднего для данных с сильной асимметрией или выбросами, может привести к смещению распределения, уменьшению вариативности и, как следствие, к ложным выводам, ухудшению качества предсказаний и даже к неправильным бизнес-решениям.
Подробнее
| импутация в статистике | импутация пропущенных значений | устранение пропусков данных | лучшие методы импутации | анализ пропущенных данных |
| импутация с помощью машинного обучения | импутация при временных рядах | импутация в Python | импутация в R | импутация в машинном обучении |